아내의 가계부를 써보자
작년 10월, 사랑하는 사람을 만나 결혼을 하게 되었습니다. 그와 동시에 연애 시절에는 생각하지 않았던 현실적인 문제들이 쏟아졌는데요, 그중 하나가 바로 가계부였습니다.
저는 9년 전 처음 취직한 뒤 다음 해에 독립을 했고, 그때부터 본격적으로 돈이 어디로 얼마나 빠져나가는지를 체감하게 되었습니다. 전기세, 가스비, 인터넷비 같은 고정 지출들이 눈앞에서 원화 단위로 빠져나가니 더는 무심할 수 없더라고요.
대학 시절의 가계부는 체크카드 내역이 전부였어요
학식, 커피, 과제 재료비 등 카테고리가 단순했기에 체크카드 내역만으로 충분했어요. 하지만 소비가 늘어나고 복잡해지면서 ‘지출 항목에 이름 붙이기’가 어려워졌습니다. 친구들과 저녁 겸 술자리를 하면, 그건 식비일까요? 술값일까요?
그때 등장한 서비스가 바로 뱅크샐러드였습니다.
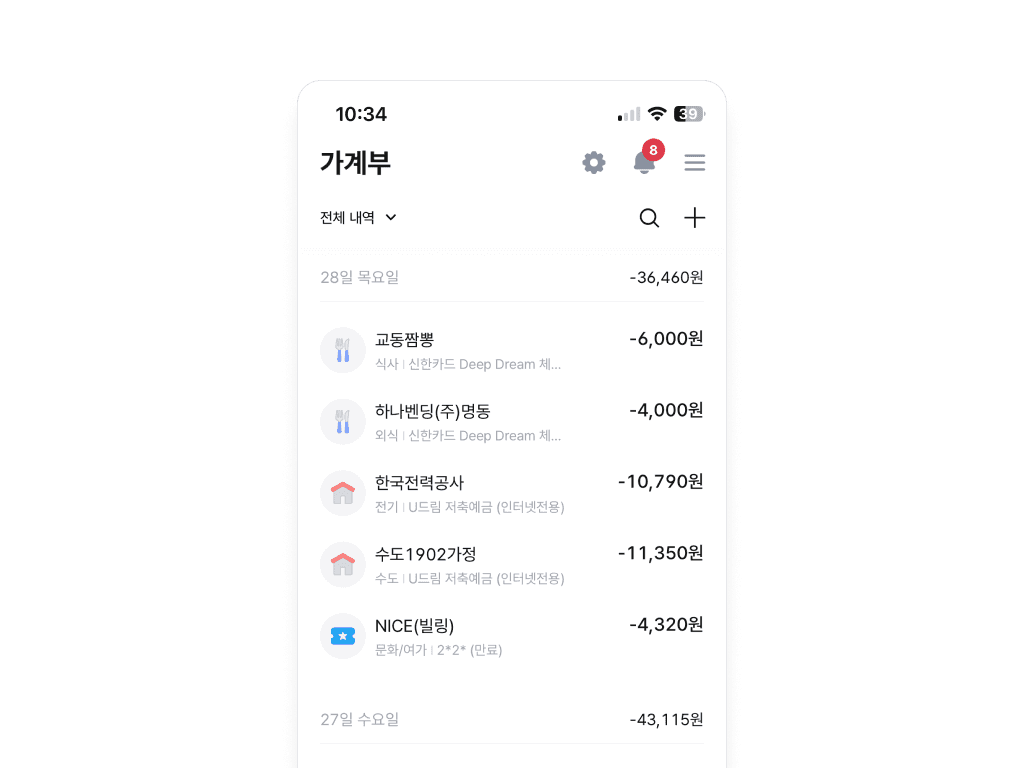
내 신용카드 내역을 긁어 자동으로 항목명을 붙여주는 뱅크샐러드 덕분에 지출 관리가 쉬워졌고, 예산 설정과 체크도 가능했죠.
그런데 어느 날, 토스 체크카드가 나타났어요

3년간 잘 쓰던 뱅크샐러드를 잠시 접게 된 계기는 토스 체크카드였습니다. 당시에는 실적 조건도, 연회비도 없고, 결제만 하면 300원씩 캐시백! 빅맥도 5,000원이 안 되는 가격에 먹을 수 있었죠. 하지만 한 가지 문제가 생겼습니다.
토스에서 쓴 내역은 뱅크샐러드에서 보이지 않았어요.
토스는 자사 앱 안에 "소비" 화면을 따로 제공했고, 캐시백 내역까지 정리해주는 편리한 구조였죠. 반면, 당시 뱅크샐러드는 타사 카드사 데이터를 스크래핑으로 받아오는 기술에 한계가 있었고, 토스는 정보를 외부에 공유하지 않았습니다. 그래서 어쩔수 없이 토스로 가계부를 옮겼지만, 제가 한 가지 간과한게 있었어요.
토스 소비 탭에는 뱅크샐러드에는 있던 "파일로 받기" 기능이 없었습니다! 전 매년 엑셀로 가계부를 정리하고 있어서 이 기능이 정말 필요했어요. 이 메뉴 저 메뉴 뒤져봤지만, 소비 내역 전체를 뽑을 수 있는 방법이 없었어요. ‘설마 안 될 리 없지’라는 저의 안일한 믿음이 문제였죠.
그래서 결국 ‘편한가계부’로 정착했습니다
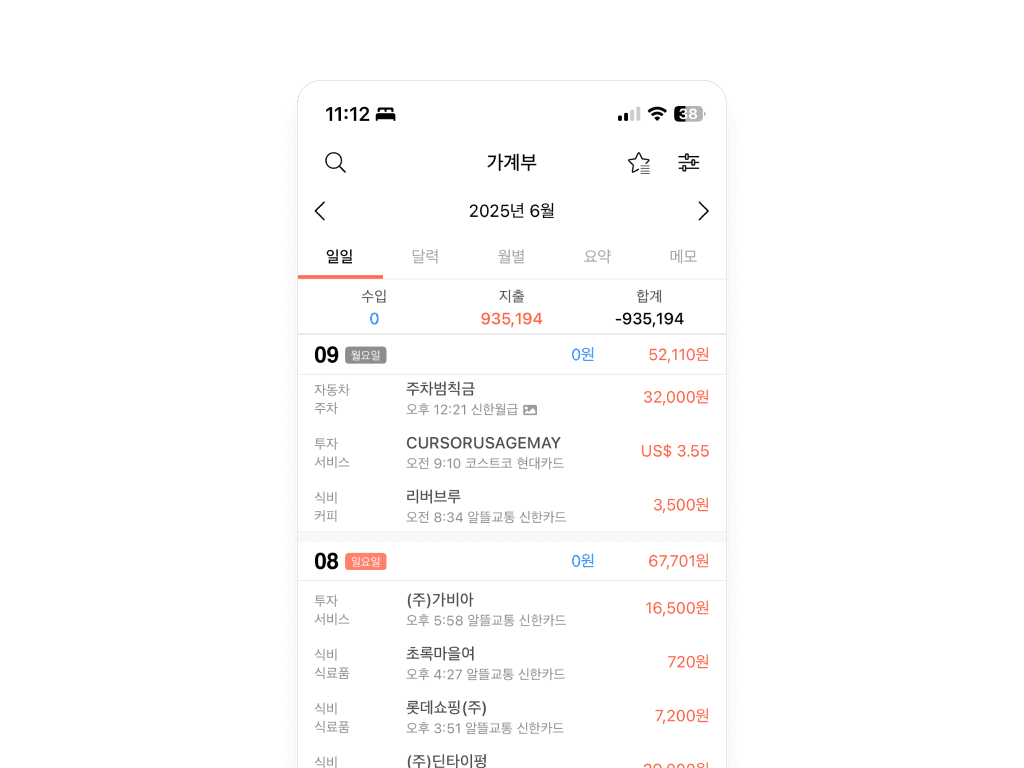
이 서비스는 단순합니다. 카드사에서 온 문자를 복사해 앱에 붙여넣기만 하면, 자동으로 이름을 붙여줍니다. 캐시백도, 항목 분류도 수작업이 필요 없어요. 아이폰의 단축어 기능을 이용하면 이 과정조차 자동화할 수 있습니다.
그리고 결혼 후, 새로운 카테고리가 생겼어요: "아내의 소비"
이 내역은 마이데이터로도, 카드 문자로도 받아볼 수 없습니다. 가장 큰 문제는, 받아본다 해도 왜 그 소비를 했는지는 직접 물어보지 않으면 절대 알 수 없다는 거예요. 만약 결제 때마다 아내에게 “왜 샀어?“라고 묻는다면… 아마 저는 지금쯤 다시 솔로로 돌아가 있겠죠. 아내에게 반복 질문은 금물이거든요. 그래서 저희는 약속을 했습니다.
투자는 아내가, 소비 관리는 내가
아내는 코로나 시절에 저점의 엔비디아를 매수한 화려한 이력이 있고, 저는 같은 시기에 고점의 지방 아파트를 매수해 -10%를 맞았습니다. 자연스러운 결정이였어요.
본격적인 아내 가계부 작성
아내는 5개 은행과 4개 신용카드를 돌려가며 혜택을 챙깁니다. 저는 각 금융사 사이트에서 실적과 내역을 다운로드해 9개 금융사의 데이터를 엑셀로 취합했죠. 무려 385개의 항목이 나왔습니다.
각 항목을 제가 만든 11개 대분류, 42개 소분류에 맞춰 분류하려니 머리가 아찔했어요. “내가 왜 이걸 하고 있지?”라는 생각이 들 무렵, Claude를 만났습니다.
AI에게 가계부를 맡겨봤습니다
최근 회사에서도 많은 업무를 자동화하고 있어서, 자연스럽게 Claude에게도 프롬프트를 작성해보았어요. 대학 시절 파이썬으로 데이터를 다뤘던 기억이 있어 명령어 작성이 어렵진 않았습니다.
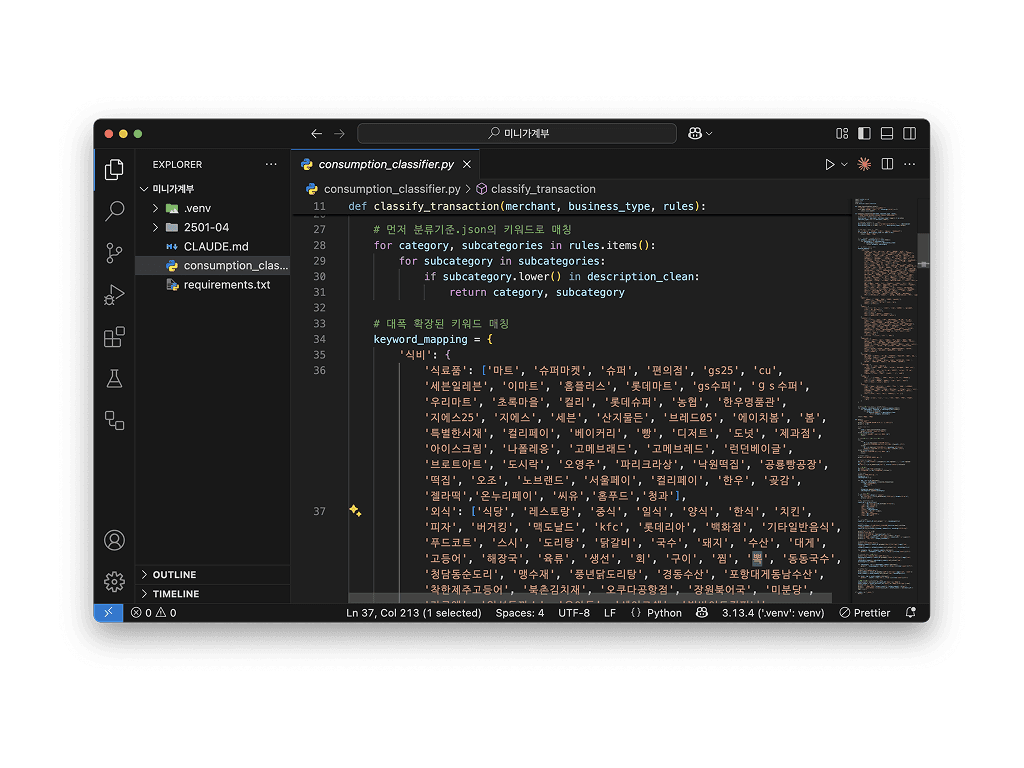
결과는 놀라웠습니다. 제 파이썬 화면엔 220줄짜리 코드가 펼쳐졌고, 그 안엔 500개가 넘는 키워드 매칭 테이블이 객체 형태로 정리되어 있었습니다.
Claude 덕분에 저는 아내에게 매일 결제 내역을 묻지 않아도 되는 남편이 되었고, 이제 분기별로 소득과 지출을 한눈에 볼 수 있는 온전한 가계부가 완성됐습니다.
마지막으로 Claude가 작성한 파이썬 코드를 공유할게요. 이 코드가 많은 가정에 평화를 가져다주길 바랍니다.
import pandas as pd
import json
import re
from datetime import datetime
def load_classification_rules():
"""분류기준.json 파일을 로드합니다."""
with open('분류기준.json', 'r', encoding='utf-8') as f:
return json.load(f)
def classify_transaction(merchant, business_type, rules):
"""거래 내용을 분석하여 분류와 소분류를 결정합니다."""
# 가맹점명과 업종을 결합해서 분석
description = f"{merchant} {business_type}".lower() if pd.notna(business_type) else str(merchant).lower()
# 특수문자 제거하되 더 관대하게
description_clean = re.sub(r'[^\w\s가-힣a-zA-Z0-9()]', ' ', description)
description_clean = re.sub(r'\s+', ' ', description_clean).strip()
# 특별 처리 - 가장 먼저 처리
etc = ['카카오페이']
if any(name in description_clean for name in etc):
return '기타', '기타'
# 먼저 분류기준.json의 키워드로 매칭
for category, subcategories in rules.items():
for subcategory in subcategories:
if subcategory.lower() in description_clean:
return category, subcategory
# 대폭 확장된 키워드 매칭
keyword_mapping = {
'식비': {
'식료품': ['마트', '슈퍼마켓', '슈퍼', '편의점', 'gs25', 'cu', '세븐일레븐', '이마트', '홈플러스', '롯데마트', 'gs수퍼', 'gs수퍼', '우리마트', '초록마을', '컬리', '롯데슈퍼', '농협', '한우명품관', '지에스25', '지에스', '세븐', '산지물든', '브레드05', '에이치봄', '봄', '특별한서재', '컬리페이', '베이커리', '빵', '디저트', '도넛', '제과점', '아이스크림', '나폴레옹', '고메브래드', '고메브레드', '런던베이글', '브로트아트', '도시락', '오영주', '파리크라상', '낙원떡집', '공룡빵공장', '떡집', '오조', '노브랜드', '서울페이', '컬리페이', '한우', '곶감', '젤라떡','온누리페이', '씨유','홈푸드','청과'],
'외식': ['식당', '레스토랑', '중식', '일식', '양식', '한식', '치킨', '피자', '버거킹', '맥도날드', 'kfc', '롯데리아', '백화점', '기타일반음식', '푸드코트', '스시', '도리탕', '닭갈비', '국수', '돼지', '수산', '대게', '고등어', '해장국', '육류', '생선', '회', '구이', '찜', '뽁', '동동국수', '청담동순도리', '풍년닭도리탕', '경동수산', '포항대게동남수산', '착한제주고등어', '북촌김치재', '오쿠다공항점', '장원북어국', '미분당', '라쿠엔', '익선돈까스', '우아동', '쉐이크쉑', '빅바이트컴퍼니', '아워홈푸디움', '에스씨케이', '짬뽕', '냉면', '족발', '보쌈', '곱창', '순대국', '김밥', '떡볶이', '분식', '샐러드바','마라탕', '마라샹궈', '족발보쌈', '곱창전골', '순대볶음', '김밥천국', '떡볶이집', '북어국', '순두부찌개', '김치찌개', '된장찌개', '비빔밥', '불고기', '갈비탕', '육회비빔밥', '냉면집', '칼국수집', '아메리칸 트레일러','제면소','우리음식','마마쿡'],
'술': ['술집', '호프', '포차', '이자카야', '막걸리', '소주', '맥주', '와인', '칵테일', '술집', '술집/호프', '호프집', '포장마차','주류'],
'커피': ['카페', '커피', '스타벅스', '투썸', '이디야', '커피전문점','공차', '테라로사', '브랜드카페', '너섬카페', '크레아찌온', '탐앤탐스', '카페꼼마','인텔리젠시아', '카페베네', '커피빈', '할리스', '빽다방', '커피숍', '커피전문점', '디저트카페','프릳츠'],
'음료': ['음료', '주스', '스무디', '쥬스', '젤라또', '벤딩머신'],
'배달': ['배달의민족', '요기요', '쿠팡이츠', '우아한형제들', '배달', '통닭']
},
'교통': {
'대중교통': ['지하철', '버스', 't머니', '교통카드'],
'택시': ['택시', '카카오택시'],
'자전거': ['따릉이', '킥고잉', '씽씽', '빔'],
'킥보드': ['킥보드']
},
'자동차': {
'충전': ['주유소', '주유', '충전소', '충전', 'sk에너지', 'gs칼텍스', 's-oil', '현대오일뱅크'],
'주차': ['주차장', '주차'],
'세차': ['세차'],
'수리': ['정비', '타이어', '엔진오일'],
'세금': ['자동차보험', '하이패스', '통행료']
},
'문화생활': {
'여행': ['여행', '호텔', '펜션', '에어비앤비', '아고다', '야놀자', '여기어때', '아시아나항공', '대한항공', '진에어', '항공', 'hilton', '힐튼', '리조트', '게스트', 'design beyond', 'eb', 'suica', 'fukuoka', 'subway', 'airport', '공항', '휴게소'],
'영화/공연/게임': ['cgv', '메가박스', '롯데시네마', '영화', '공연', '콘서트', '스팀', '넷플릭스', '왓챠', '디즈니'],
'음악/도서': ['음악', '도서', '책', '영풍문고', '교보문고', '알라딘', '인터파크도서', 'yes24', '반디앤루니스', '영화예매', '공연예매'],
'어플': ['애플', '구글플레이', '앱스토어', '앱', '어플', '구독', '인앱결제', '인앱'],
'캠핑': ['캠핑'],
'온천/마사지': ['온천', '마사지', '스파']
},
'패션/미용': {
'의류': ['유니클로', '자라', '무신사', '옷', '신발', '가방', 'h&m', '스파오', '탑텐', '지오다노', '나이키', '아디다스', '칼하트', '이랜드', '브라더스스토어', '파타고니아', '아이갓에브리띵'],
'화장품': ['올리브영', '이니스프리', '화장품', '에뛰드', '미샤', '세포라', '아모레퍼시픽', '베네피트', '엘지생활건강', '샴푸', '포비브라이트', '블루쥬얼리'],
'헤어': ['손보연','미용실', '헤어샵', '엠에이치앤코모던', '헤어샵', '미용실', '네일샵', '네일아트', '속눈썹연장', '왁싱'],
'세탁': ['세탁소']
},
'생활용품': {
'가구/가전': ['다이소', '이케아', '코스트코', '전자제품', '가전', '가구', '하이마트', '전자랜드', '삼성디지털프라자'],
'주방/욕실': ['주방', '욕실'],
'잡화': ['쿠팡', '11번가', 'g마켓', '옥션', '네이버쇼핑', '더현대', '신세계', '롯데쇼핑', '아울렛', '현대백화점', '백화점']
},
'주거/통신': {
'관리비': ['관리비', '아파트'],
'공과금': ['전기', '가스', '수도', '공과금', '도시가스', '에너지공사', '서울에너지'],
'통신비': ['kt', 'skt', 'lg유플러스', '인터넷', '핸드폰', '휴대폰', '통신', 'lg전자', '구독료'],
'이자월세': ['월세', '이자','대출상환', '대출', '상환']
},
'경조사': {
'결혼/부고': ['축의금', '부의금', '결혼식', '장례식'],
'선물': ['선물', '화환'],
'헌금': ['헌금', '조계종', '조계사', '불교', '교회', '성당'],
'예식': ['예식', '돌잔치', '백일']
},
'건강': {
'운동': ['김원', '필라테스', '헬스장', '체육관', '요가', '피트니스', '운동', 'pt', '퍼스널트레이닝'],
'병원': ['병원', '의원', '한의원', '종합병원', '대학병원', '내과', '외과', '이비인후과', '정신과', '산부인과', '소아과', '비뇨기과', '신경과', '심리상담'],
'보험': ['보험', '치과', '안과', '정형외과', '피부과']
},
'투자': {
'서비스': ['증권', '주식', '펀드', '적금', '예금', '연금', '퇴직금', '투자']
}
}
# 키워드 매칭으로 분류 (대소문자 무시)
for category, subcategory_dict in keyword_mapping.items():
for subcategory, keywords in subcategory_dict.items():
for keyword in keywords:
if keyword.lower() in description_clean:
return category, subcategory
return '기타', '기타'
def main():
"""메인 함수"""
print("🛒 소비내역 분류기 v2.0 (개선된 키워드)")
print("=" * 60)
# 분류 규칙 로드
try:
rules = load_classification_rules()
print("✅ 분류기준.json 로드 완료")
except Exception as e:
print(f"❌ 분류기준.json 로드 실패: {e}")
return
# 소비내역 파일 읽기 (xlsx 또는 csv)
try:
try:
df = pd.read_excel('소비내역.xlsx')
print(f"✅ 소비내역.xlsx 파일 로드 완료 ({len(df):,}건)")
except:
df = pd.read_csv('소비내역.csv', encoding='utf-8-sig')
print(f"✅ 소비내역.csv 파일 로드 완료 ({len(df):,}건)")
except Exception as e:
print(f"❌ 소비내역 파일 로드 실패: {e}")
return
# 데이터 전처리
print("\n📊 데이터 전처리 중...")
# 이용금액을 숫자로 변환
df['금액'] = df['이용금액'].astype(str).str.replace(',', '').str.replace('원', '')
df['금액'] = pd.to_numeric(df['금액'], errors='coerce').fillna(0)
# 빈 값 처리
df['업종'] = df['업종'].fillna('')
df['이용가맹점'] = df['이용가맹점'].fillna('')
# 분류 진행
print("🔍 거래 분류 중...")
categories = []
subcategories = []
for idx, row in df.iterrows():
category, subcategory = classify_transaction(
row['이용가맹점'],
row['업종'],
rules
)
categories.append(category)
subcategories.append(subcategory)
# 날짜 형식 처리
if df['이용일자'].dtype == 'object':
df['이용일자'] = pd.to_datetime(df['이용일자'], format='%Y.%m.%d', errors='coerce')
# 결과 DataFrame 생성
result_df = pd.DataFrame({
'날짜': df['이용일자'].dt.strftime('%Y-%m-%d'),
'시간': df['이용시간'],
'자산': df['이용카드'],
'분류': categories,
'소분류': subcategories,
'금액(원)': df['금액'].abs(),
'화폐구분': 'KRW',
'내용': df['이용가맹점'],
'메모': df['업종']
})
# 날짜순 정렬
result_df = result_df.sort_values('날짜', ascending=False)
# CSV로 저장
output_filename = f'최종_분류된_소비내역_{datetime.now().strftime("%Y%m%d_%H%M%S")}.csv'
result_df.to_csv(output_filename, index=False, encoding='utf-8-sig')
print(f"\n" + "=" * 60)
print(f"✅ 분류 완료!")
print(f"📊 총 거래 수: {len(result_df):,}개")
print(f"💰 총 금액: {result_df['금액(원)'].sum():,.0f}원")
print(f"📅 기간: {result_df['날짜'].min()} ~ {result_df['날짜'].max()}")
print(f"💾 저장된 파일: {output_filename}")
# 분류별 요약
print(f"\n📈 분류별 요약:")
category_summary = result_df.groupby('분류')['금액(원)'].agg(['sum', 'count'])
category_summary = category_summary.sort_values('sum', ascending=False)
for category, row in category_summary.iterrows():
print(f" {category}: {row['sum']:,.0f}원 ({int(row['count'])}건)")
# 소분류별 요약 (상위 15개)
print(f"\n🏷️ 소분류별 요약 (상위 15개):")
subcategory_summary = result_df.groupby('소분류')['금액(원)'].agg(['sum', 'count'])
subcategory_summary = subcategory_summary.sort_values('sum', ascending=False).head(15)
for subcategory, row in subcategory_summary.iterrows():
print(f" {subcategory}: {row['sum']:,.0f}원 ({int(row['count'])}건)")
# 자산별 요약
print(f"\n💳 자산별 요약:")
asset_summary = result_df.groupby('자산')['금액(원)'].agg(['sum', 'count'])
asset_summary = asset_summary.sort_values('sum', ascending=False)
for asset, row in asset_summary.iterrows():
print(f" {asset}: {row['sum']:,.0f}원 ({int(row['count'])}건)")
# 기타 분류가 얼마나 남았는지 확인
others_count = len(result_df[result_df['분류'] == '기타'])
others_amount = result_df[result_df['분류'] == '기타']['금액(원)'].sum()
print(f"\n❓ 개선 결과:")
print(f" '기타' 분류: {others_count}건 ({others_amount:,.0f}원)")
print(f" 분류 정확도: {((len(result_df) - others_count) / len(result_df) * 100):.1f}%")
if __name__ == "__main__":
main()
댓글 (0)
아직 댓글이 없습니다.